

Reducing Dashboard Latency and Improving Data Pipeline Observability
Abstract
Our client, a leading FinTech SaaS provider, offers an AI-powered platform that transforms complex financial documents into structured, decision-ready data for global credit market participants. However, as the volume of ingested data grew, key dashboards suffered from performance issues, with query latencies exceeding 10 seconds - hindering time-sensitive workflows for end users.
We conducted a deep audit of their ML-to-database pipeline, identified inefficiencies in data modeling and ingestion architecture, and proposed a scalable redesign. By rearchitecting the data model and introducing Temporal-based orchestration, we significantly reduced dashboard latency, improved reliability of ingestion jobs, and enhanced observability across the data stack.
Overview
Our client is a rapidly growing SaaS company in the FinTech space, serving a global customer base that includes private credit funds, investment banks, and rating agencies. Their platform enables these institutions to turn unstructured financial and legal documents into structured, decision-ready data—empowering faster due diligence, streamlined covenant monitoring, and greater visibility into portfolio performance.
At the core of their offering is an AI-native platform that leverages advanced machine learning (ML), natural language processing (NLP), and optical character recognition (OCR) to extract insights from documents such as credit agreements, term sheets, and compliance reports—delivering results within minutes.
We were brought in to address performance issues affecting the platform’s downstream analytics layer, particularly dashboard latency and post-processing of ML-generated data. Our goal was to audit the existing data pipeline, identify bottlenecks, and design a scalable, observable, and high-performance solution.
Problem Statement
The client’s machine learning pipeline processes large volumes of complex financial documents, generating semi-structured JSON outputs that are parsed and stored in SQL Server across multiple relational tables. However, during downstream consumption—particularly in dashboard queries - response times frequently exceeded 10 seconds in high-load scenarios. This latency often degraded the user experience and posed challenges for time-sensitive investment workflows.
The performance issues hinted at deeper inefficiencies in data modeling, query optimization, and infrastructure scalability. We were brought in to conduct a comprehensive audit of the data pipeline - from ML data ingestion to storage and retrieval - with the goal of identifying bottlenecks, improving query performance, and enhancing system observability to support scale and reliability.
Observations & Proposed Design
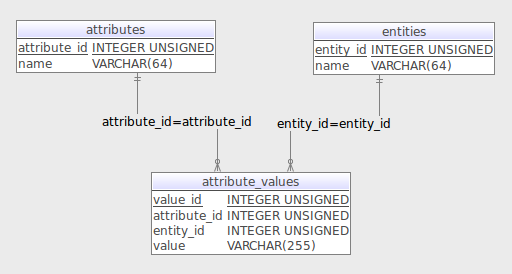
Existing Data Modelling
The existing system used an EAV (Entity–Attribute–Value) data model. This approach is flexible, that allows schema-less extensibility when new attributes are added or when not all rows share the same attributes.
However, this introduces significant performance drawbacks:
Complex queries require multiple self-joins across rows of the same logical entity
Composite filtering keys degrade query speed
Analytical or roll-up queries over a batch of line items are inefficient and slow
Proposed Data Model
We observed that dashboard queries typically retrieve all line items related to a specific document (doc_table_id). Rarely are individual or selective line items queried in isolation. Based on this, we proposed a simplified and optimized table structure:
This model eliminates excessive joins and allows for efficient batch reads and aggregations across all line items for a document—drastically improving query speed and maintainability.
Data retrieval queries for this product are usually against multiple line items of the same table id i.e. all line items of the table id are retrieved together instead of filtering for 1-5 line items of the same table.
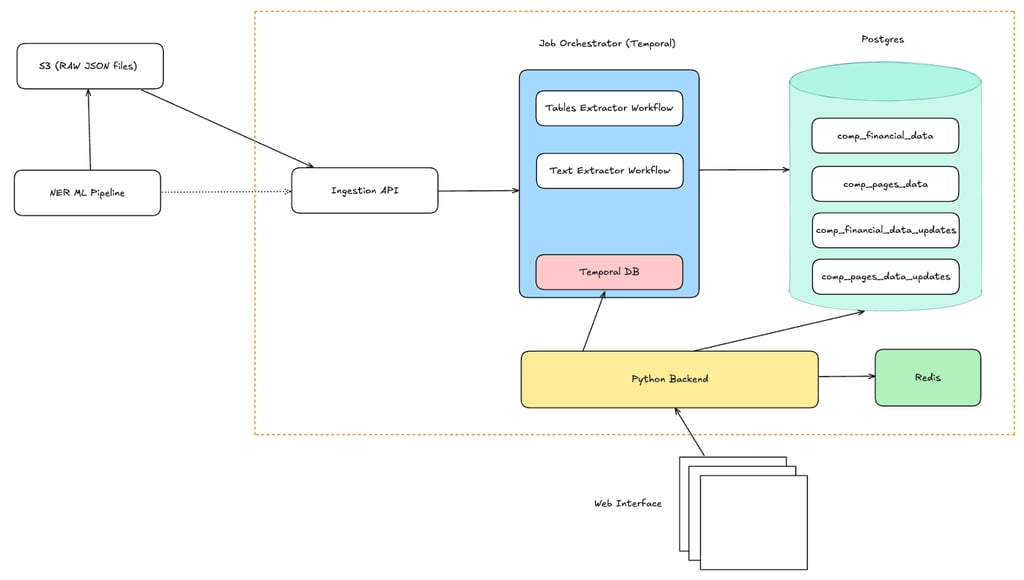
Improving Observability of Data pipelines
This solution not only resolves current challenges but also establishes a foundation for advanced analytics and AI/ML use cases, enabling the client to harness their data more effectively. Investing in a scalable and future-proof data platform is essential for organizations looking to drive innovation and maintain a competitive edge in today’s data-driven landscape
The existing ingestion pipeline was tightly coupled with the application’s API framework. Long-running ingestion jobs lacked visibility, error tracking, or retry mechanisms. Failures were hard to detect and diagnose, which impacted reliability.
To address this, we proposed adopting Temporal as an orchestration layer for ML ingestion workflows. With Temporal, ingestion jobs can benefit from:
Native support for retries and error handling
Logging and progress tracking across multi-step workflows
Improved observability of pipeline health and failures
Decoupling ingestion from API control flow, leading to more maintainable and scalable architecture
We have proposed Temporal based orchestration for the data ingestion jobs, when data needs to be ingested from ML pipelines. The existing system relies entirely on the API framework for ingestion jobs. For long-running jobs which can require retries, logging, better observability of failed jobs; it would be ideal to adopt an Orchestration tool to handle this better.
Potential Benefits
The proposed solution unlocks faster access to data, improving dashboard performance and enhancing the user experience. By introducing orchestration and observability, the data pipeline becomes more reliable and easier to monitor. The simplified data model supports scalability and maintainability, enabling the platform to handle growing data volumes while delivering timely, decision-ready insights to end users.
CREATE TABLE financial_line_items (
id SERIAL PRIMARY KEY,
doc_table_id INTEGER NOT NULL, -- or BIGINT if you may have many documents
path JSONB NOT NULL, -- e.g. ['Assets', 'Current Assets', 'Cash']
value NUMERIC,
statement_type TEXT
);