

Migrating to AWS Glue based Data Lakehouse from Postgres database
Abstract
Our client is a B2B product company in the e-commerce industry seeking to transition to a modern data architecture. Their goal is to adopt an Open Data Lakehouse approach by migrating their analytics data from PostgreSQL to a more scalable and performant data stack. We proposed and demonstrated a Delta Lake based Lakehouse solution on AWS, utilizing S3 for data storage and AWS Glue as the data catalog. This setup provided the client with a unified, open table format capable of handling large-scale data while offering improved performance and compatibility with multiple query engines.
This case study highlights the implementation of a Delta Lake based Lakehouse to enhance scalability, streamline data analytics workflows, and support future growth. It emphasizes the critical role of modern data platforms in empowering organizations to derive actionable insights and maintain a competitive edge in fast-evolving industries.
Overview
As data volumes grow and analytical needs become increasingly complex, modernizing data infrastructure is crucial for scalability and efficiency. Our client, a B2B product company in the e-commerce industry, faced challenges with their PostgreSQL database such as slow retrieval and lack of flexibility in the architecture to adapt to new business requirements.
Their data, comprising first-party (1P) and third-party (3P, crawled) data from multiple e-commerce marketplaces, powers analytical products for reporting and dashboarding while serving the needs of Data Analysts, Data Scientists, and ML Engineers for ad hoc querying and development purposes.
Problem Statement
The client faced several challenges in managing their analytics infrastructure due to limitations in their existing PostgreSQL setup:
Performance Bottlenecks: The current data model is normalized to minimize redundancy, but this design results in significant performance challenges for analytical queries, especially those requiring joins across multiple tables with large datasets.
Tightly Coupled Compute and Storage: PostgreSQL as a database has both the compute and storage tightly coupled together. This leads to the requirement of powerful host machines with a high number of CPU cores as well as a good amount of storage and memory.
Compute Constraints: Running historical data analysis on the PostgreSQL database impacts operational reporting performance. Data Analysts and ML Engineers require elastic, ad hoc compute capabilities, which are currently constrained by the fixed compute resources allocated to PostgreSQL.
Query Prioritization and SLAs: The business requires priority-based query execution across systems, but the current PostgreSQL infrastructure lacks this capability. Additionally, analytical applications require query responses to meet stringent SLA requirements, which are challenging to achieve with the existing setup.
Existing Environment
In the existing setup, the client stores their first-party (1P) and third-party (3P) crawled data in MongoDB. A Prefect-based Python job extracts data from MongoDB, applies transformations, and loads it into a PostgreSQL database. The infrastructure consists of separate PostgreSQL instances dedicated to transactional operations, reporting, and backups.
The data ecosystem faces several operational challenges:
High Maintenance Effort: The database infrastructure demands substantial maintenance, which slows down business growth.
Scalability Issues: With a data volume of 16TB growing at a rate of 10–12GB (compressed) daily, the system struggles to manage the increasing load.
Manual Updates: Key PostgreSQL tables are regularly updated using CSV files, adding to the operational complexity.
Performance Constraints: At peak times, the PostgreSQL instances handle around 190 connection pools, each managing multiple queries, leading to resource contention and degraded performance.
These challenges highlight the need for a scalable, efficient, and modernized data architecture to support the client’s growing analytical and business needs.
Proposed Solution and Architecture
Our proposed architecture included the following components of the solution mosaic:
Migration to Data Lakehouse
To address the scalability and performance limitations of the existing PostgreSQL system, we proposed migrating the data infrastructure to a Data Lakehouse using Delta Lake as the table format. This transition ensures ACID compliance, supports schema evolution, and offers high-performance querying.
Medallion Architecture for Data Modelling
The Lakehouse architecture was designed following the Medallion pattern, where data is organized into bronze, silver, and gold layers:
Bronze Layer: Raw data ingested from MongoDB is stored in its native form.
Silver Layer: A transpiled version of the existing Prefect Python jobs, now written in PySpark, processes the Bronze layer data, cleansing and transforming it into structured datasets. Transpiling refers to converting source code written in one language or framework into equivalent code in another language or framework, maintaining functionality while enabling compatibility with different technologies.
Gold Layer: Further transformations and aggregations are performed using Spark SQL jobs to produce refined, rolled-up datasets for analytics and reporting use cases.
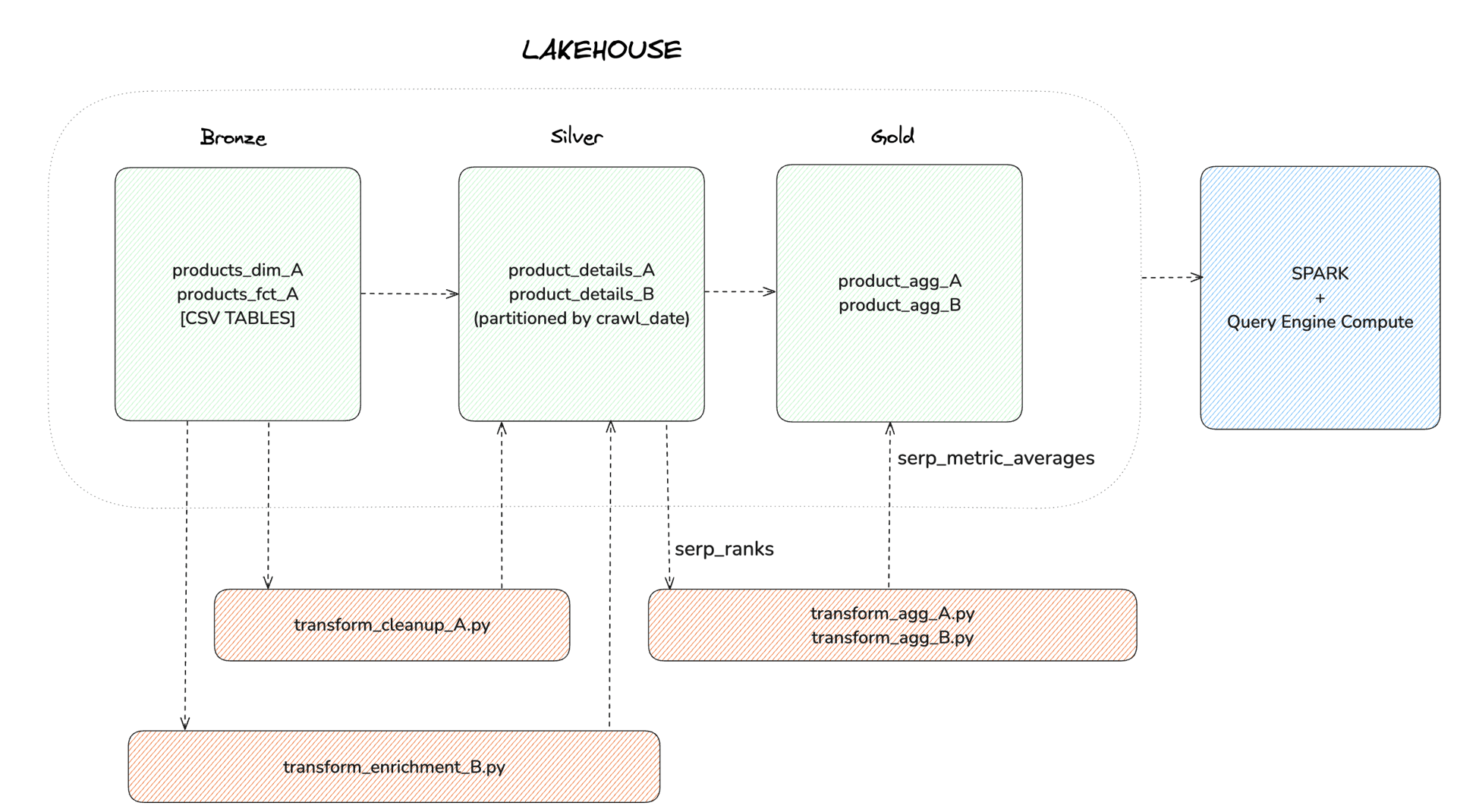
Compute and Querying Solutions
We recommended using Apache Spark for large-scale data processing, and the client expressed interest in exploring a third-party compute engine as the query engine to support analytical and ad hoc queries. This compute engine offers efficient querying of Silver and Gold layer tables, ensuring seamless performance for diverse analytical workloads.
End-to-End Workflow
Data Ingestion: Data from MongoDB is ingested into the Bronze layer of the Lakehouse.
Data Transformation: PySpark jobs, adapted from the existing Prefect workflows, cleanse and structure the data into Silver layer tables.
Aggregation and Roll-ups: Spark SQL jobs process the Silver layer data to produce aggregated insights, stored in the Gold layer.
Query Serving:
Silver Layer: Supports detailed analysis and development needs for data scientists and analysts.
Gold Layer: Provides optimized data access for dashboards, reporting, and business analytics.
Performance Optimization and Maintenance
To ensure high performance and scalability, the following optimizations were proposed:
Partitioning: Strategic partitioning of tables across the Bronze, Silver, and Gold layers to enhance query performance.
Delta Maintenance Operations: Scheduling Delta Lake maintenance tasks such as data compaction, vacuuming, and checkpointing to manage metadata growth and maintain efficient storage.
Elastic Scalability: Leveraging Spark’s distributed computing capabilities and the third-party compute engine's performance optimizations to handle increasing data volumes and concurrent queries.
This architecture modernizes the client’s data infrastructure, enabling robust support for analytics applications, ad hoc querying, and future data growth.
Implementation
The implementation of the proposed solution was carried out in a phased manner, ensuring seamless migration and minimal disruption to existing operations. The following steps summarize the process:
Data Lakehouse Setup and Configuration
Delta Lake Configuration: The Delta Lake environment was set up on AWS S3 for data storage. Necessary configurations for Delta Lake tables, such as partitioning and metadata management, were established.
Medallion Architecture Modeling: The Lakehouse was organized into Bronze, Silver, and Gold layers, each serving distinct purposes in the data processing pipeline.
Data Ingestion and Transformation Pipelines
Data Ingestion: A PySpark-based pipeline was developed by transpiling the existing Prefect Python jobs. This pipeline reads raw data from MongoDB and writes it into the Bronze layer tables, retaining its original format for traceability.
Data Cleansing and Structuring: Another PySpark pipeline processed the Bronze layer data, performing cleansing, deduplication, and structuring tasks to generate Silver layer tables.
Aggregation and Roll-ups: Spark SQL jobs were implemented to perform advanced transformations on the Silver layer data, creating aggregated, rolled-up datasets in the Gold layer for reporting and analytics use cases.
Querying and Analytics
Third Party Query Engine Integration: The third-party query engine was configured to interact with the Lakehouse, enabling fast and efficient querying of Silver and Gold layer tables. This integration ensured that SLAs for dashboards and analytics applications were consistently met.
Support for Ad Hoc Queries: Data analysts and scientists were provided direct access to the Silver layer for detailed analysis and to the Gold layer for quick insights.
Optimization and Maintenance
Performance Tuning: Delta Lake optimizations such as compaction and partitioning were applied to ensure efficient query performance and storage utilization.
Automated Maintenance: Scheduled Delta Lake maintenance tasks, including vacuuming and checkpointing, were implemented to manage table growth and maintain metadata health.
Outcomes
Improved Query Performance: The transition to the Lakehouse architecture significantly reduced query response times for dashboards and analytics.
Scalability: The new infrastructure effortlessly handled the growing data volumes and increased concurrent query demands.
Enhanced Collaboration: Data scientists and analysts experienced improved flexibility and faster access to data for ad hoc exploration and model development.
This implementation not only modernized the client's data infrastructure but also provided a robust foundation for future scalability and advanced analytics.
Future Scope
The implemented Data Lakehouse solution lays the foundation for several advancements and enhancements in the future:
Wider Adoption of the Data Lakehouse Platform
Expanding the Data Lakehouse’s utilization beyond the current analytics and reporting use cases to support advanced AI/ML workflows. By leveraging Delta Lake’s scalability and performance, the platform can provide robust data pipelines for model training, validation, and deployment, ensuring seamless integration with existing and future machine learning frameworks.
Schema Evolution Alerting Mechanism
Implementing an automated alerting mechanism to detect and notify users of schema changes in real-time. This enhancement will proactively inform data engineers and analysts, enabling them to address potential compatibility issues or adjust downstream processes promptly, ensuring uninterrupted operations.
Advanced Data Governance and Cataloging
Introducing advanced data governance features, such as integrating with a data catalog solution, to provide improved discoverability and traceability. This would empower users with better metadata management, lineage tracking, and access controls, fostering a more collaborative and secure data environment.
These future improvements aim to maximize the platform's potential, driving greater adoption, resilience, and innovation across the organization.
Conclusion
The transition to a Data Lakehouse architecture using Delta Lake has positioned the client to overcome the limitations of their legacy Postgres-based infrastructure. By adopting the Medallion architecture and leveraging modern compute solutions like Apache Spark and third-party query engine, the client has achieved enhanced scalability, improved query performance, and streamlined data workflows.
This solution not only resolves current challenges but also establishes a foundation for advanced analytics and AI/ML use cases, enabling the client to harness their data more effectively. Investing in a scalable and future-proof data platform is essential for organizations looking to drive innovation and maintain a competitive edge in today’s data-driven landscape