

Designing Data Lakehouse with Apache Iceberg
Abstract
Our client is a customer engagement SaaS product company who needed to revamp their data lake architecture to address issues of data consistency and schema evolution. Specifically, they required an upgrade to their CDC system, which replicates transactional database tables to an S3-based data lake. We proposed and demonstrated the implementation of Apache Iceberg, a high-performance open table format for their data Lakehouse. This solution efficiently managed their large datasets and addressed the constantly evolving data schema challenges associated with onboarding new customers. Apache Iceberg provided ACID transactions, improved query performance, and seamless schema evolution across different compute engines like Spark, Trino, and Flink.
This case study explores the implementation of Apache Iceberg to address challenges in data management and highlights the potential benefits of modern data solutions. It underscores the importance of aligning technical projects with organizational goals to achieve optimal outcomes.
Overview
In the age of big data, it's essential to manage and update data infrastructure to meet evolving business needs and customer demands. Our client, a customer engagement SaaS product company, faced significant challenges with their data lake architecture, particularly around handling schema evolution and ensuring data consistency while reading data from Data Lake through Flink, their compute engine.
Problem Statement
The client was facing the following issues while managing their production data on a day-to-day basis.
Data Inconsistency: The existing system suffered from data inconsistencies, especially when using different compute engines like Spark, Trino, and Flink; where the data written from one platform is not consistent with the data read from another
Schema Evolution Challenges: The client's data schema frequently updates with new columns or changes in data type. These schema changes result in inconsistent data across partitions of the same table, leading to inaccurate results when running queries over multiple partitions.
Complex Data Management: The previous architecture often struggled to manage the large, diverse datasets efficiently.
Existing Environment
In the current setup, user data from their SaaS product is stored in MongoDB. A Kafka Connect-based Debezium connector reads the data from MongoDB and publishes it to Kafka. A custom Kafka sink connector then converts the AVRO-formatted data in Kafka to Parquet format and writes it to an S3-based data lake, partitioned by tenant identity attribute and date.
Our study and analysis revealed that the existing system struggled to handle large-scale data efficiently and maintain their consistency. The system faced challenges with schema evolution and data replication, making it difficult to ensure data accuracy and timely data availability.
Proposed Solution and Architecture
Our proposed architecture included the following components of the solution mosaic:
Migration to Iceberg Table Format: Transitioning all datasets to Apache Iceberg to leverage its advanced data handling capabilities.
Schema Evolution Support: Utilizing Iceberg's features to manage schema changes seamlessly.
Efficient Partitioning and Compaction: Designing a system to improve query performance and manage data efficiently.
Integration with Existing Systems: Maintaining compatibility with the current analytics engines, including Spark and Trino.
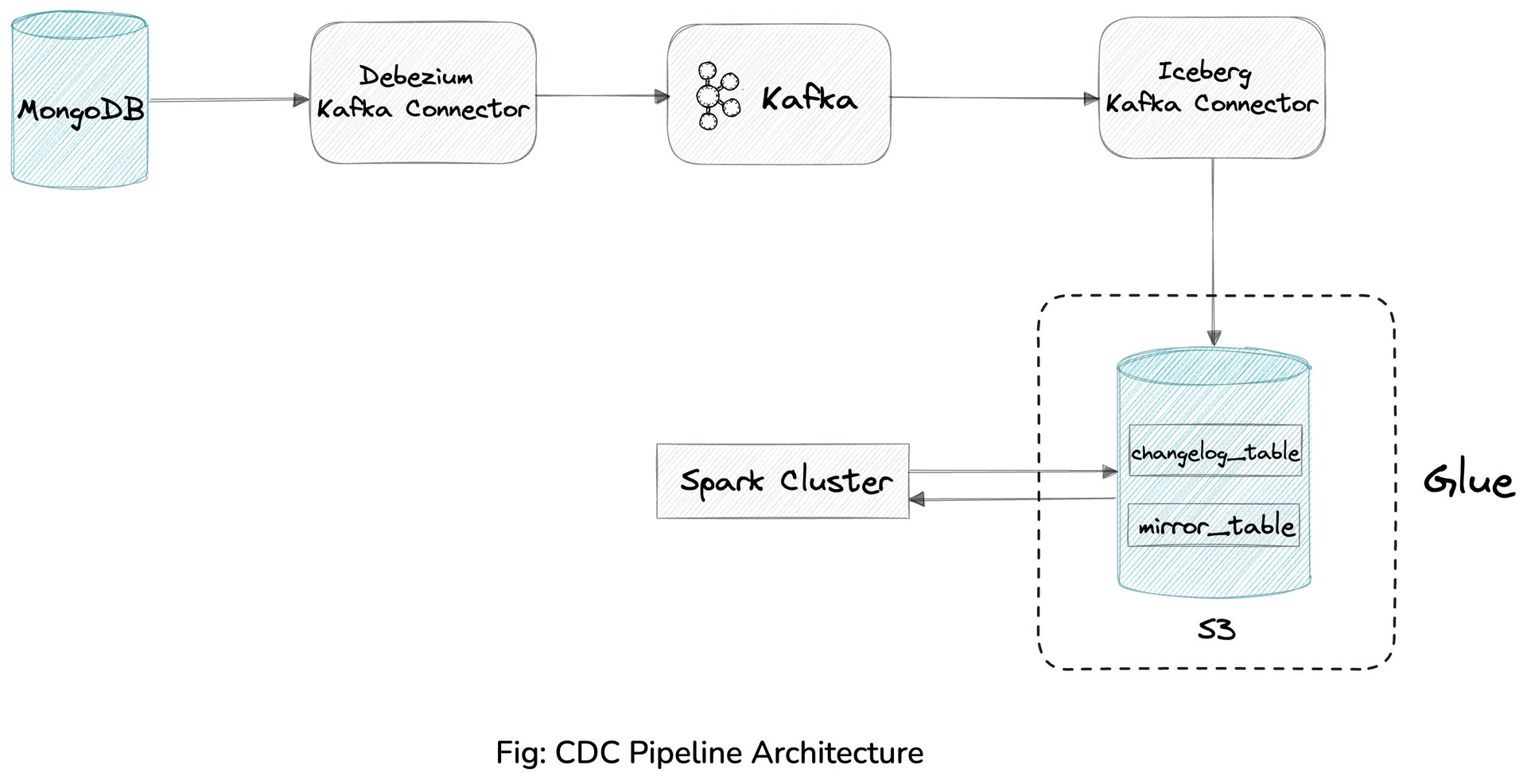
As the CDC data from MongoDB becomes available in Kafka, the Iceberg kafka connector consumes this data and writes this data to the Glue changelog table with a flush interval of 180 seconds. A Spark SQL job then triggers the MERGE operation on the Mirror table using the changelog data to perform the merge operation.
When the data is synced to the changelog table, ordering of the data may not always be accurate. To address this, we found it beneficial to add timestamps at various stages of the pipeline, such as during sourcing to or sinking from Kafka, and while merging from the changelog to the mirror table.
As the mirror table is updated regularly through the MERGE operation, numerous Iceberg metadata files and smaller data files are created with each update. This accumulation can potentially slow down read operations on the tables. Therefore, we found it essential to perform Iceberg maintenance operations such as compaction, snapshot expiration, and setting the appropriate expiration value for retaining the oldest metadata versions.
Potential benefits of adopting Apache Iceberg (an Open Table Format)
We picked Apache Iceberg for our data management solution by considering a few key features.
Its support for ACID transactions ensures data consistency and reliability, making it a robust choice for maintaining accurate data states. The platform's capabilities in schema evolution simplify the management of changing data structures, while its partitioning and compaction features enhance data storage, improve performance, reduce query response times, and enhance overall operational efficiency. Additionally, the time travel feature allows access to historical data, facilitating audits and debugging processes. Apache Iceberg's compatibility with existing analytics frameworks further streamlined its integration into our system. Finally, Apache Iceberg provides scalability, making it well-suited to accommodate future expansion and increased data loads, thereby future proofing our data infrastructure.
However, like any new solution, it presents certain challenges, such as the initial complexity of migration, a learning curve for new users, and overhead in managing metadata and transactional logs. Our team has the expertise and is well-equipped to address these challenges by providing comprehensive migration planning, user training, and efficient metadata management strategies. This enables businesses to fully leverage Apache Iceberg's capabilities while minimizing potential drawbacks.
Using Iceberg maintenance operations like data files compaction is really helpful in solving the small files problem which can be a common scenario in a CDC system. Merging the small files into the pre-configured target-file-size-bytes (128MB in this case) not just helps in saving the storage space but also the performance of queries over the data.
Conclusion
This case study highlights the potential advantages of adopting modern data management solutions like Apache Iceberg. It also underscores the importance of aligning technical projects with broader organizational goals and ensuring adequate resources and support for implementation. For our client, future considerations will involve reassessing the need for data infrastructure upgrades and exploring new strategies to achieve their data management objectives. Adopting an open table format like Iceberg, supported by multiple compute engines and programming languages (such as Python and Rust), broadens opportunities to use data not just for analytical workloads but also for AI/ML, providing various options for organizational teams to leverage data to its full potential.