Data Preprocessing using Spark for AI Product
Data Preprocessing using Spark for AI Product
Abstract
Our client faced challenges with data duplication in public datasets used for training language models, which led to bias and reduced model performance. To address this, we implemented a fuzzy deduplication algorithm using Spark and PySpark, effectively removing duplicates and enhancing model generalization and computational efficiency. The solution involved storing data in S3 and processing it with AWS EMR clusters. The implementation achieved an 80% accuracy in duplicate identification and improved overall performance. This robust data engineering approach significantly reduced bias, resulting in more reliable AI/ML model predictions.
Overview
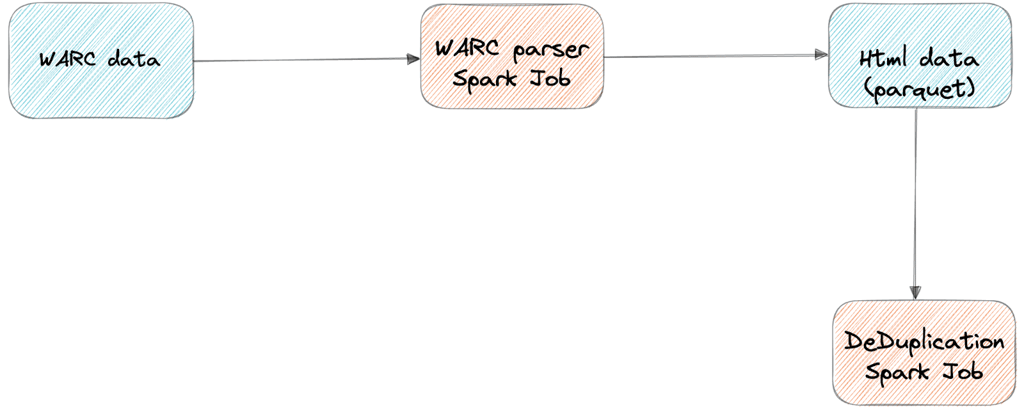
Our client uses various public datasets from the web to train their language model. However, they often encounter issues with duplicated data, which can slow down the process and introduce bias into the model. To address this, we developed a solution that includes a fuzzy deduplication algorithm to eliminate duplicates across these datasets. Additionally, the solution features a pipeline that processes public web archive WARC files by extracting the HTML content from each record, removing the WARC metadata, and preparing the data for further processing.
Problem Statement
Duplication of data in these public datasets leads to bias in model training, as the repeated instances can disproportionately influence the learning process. This overrepresentation can cause the model to learn patterns that are not truly representative of the underlying data distribution. Consequently, the model may become overly sensitive to the duplicated records, skewing its predictions towards these biases. This ultimately lowers the quality of the model, as it fails to generalize well to new, unseen data and may make inaccurate predictions in real-world scenarios.
Recommendation
Our recommendation included Deduplication of data as the first step which would overcome this bias by identifying all records with uniform priority. This process ensures that each unique instance is represented only once, reducing the risk of overfitting and enhancing the model's generalisation capabilities. Furthermore, deduplication improves computational efficiency by decreasing the volume of data the model needs to process. By maintaining a clean and accurate dataset, we can achieve more reliable predictions and a clearer understanding of the model's performance.
Proposed Solution and Architecture
Our proposed solution involved using Spark as the transformation engine to identify duplicates using a fuzzy deduplication logic written in PySpark. According to this logic, two web pages were considered similar if their Jaccard similarity distance was less than a 0.2 threshold.
We utilised S3 as the Data Lake to store input WARC files, parquet files, and the final set of deduplicated data. A Single crawl of Common Crawl data, after conversion to parquet, took about 1TB of space in S3. Since we used 12 months of data for deduplication, it amounted to approximately 12TB.
To provision the Spark cluster and deploy the PySpark pipelines, we used Amazon EMR. For the WARC parser pipeline, we set up an EMR cluster with 30 nodes of r5d.24xlarge instance type. For the De-Duplication job, we set up an EMR cluster with 80 nodes of r5d.24xlarge instance type.
Architecture Diagram
Implementation
The WARC parser and deduplication pipelines are implemented using the PySpark API, with configurations like input and output data paths maintained in JSON config files. A Python script based on the AWS SDK launches the AWS EMR cluster with the required configuration and initiates the Spark job. Both pipelines are manually invoked whenever a new dataset needs to be absorbed into the system or when there is a change in the deduplication logic.
The fuzzy deduplication process successfully identified 80% of the duplicates with a fair amount of accuracy. Initially, we used a combination of LEFT JOIN and a filter condition to eliminate duplicate records, but we later switched to a Spark LEFT_ANTI join. This change simplified the process and improved performance while maintaining the same level of accuracy.
Future Scope
In the current approach, duplicate pairs are identified using fuzzy deduplication logic. However, it could be beneficial to identify connected duplicates as well. For example, if (R1, R2) and (R2, R3) are identified as duplicates, we could ideally retain only R1 as the original. Achieving this requires creating a connected graph to identify the root parents that need to be retained while filtering out all children of the root node at different levels.
Conclusion
A robust data engineering workflow can significantly enhance the quality of AI/ML models, as demonstrated in this case study. By employing both parser and deduplication pipelines, we successfully eliminated redundant data, thereby avoiding unwanted bias in the system. Investing in a comprehensive data engineering stack is highly recommended for any AI/ML use case. We would highly recommend adopting a comprehensive data engineering stack to optimize any AI/ML use case and ensure the best outcomes.