Streamlining Resume Search, Screening, and Scoring for Niche Talent Recruitment
The Challenge
Apache Iceberg has quickly become a cornerstone of modern Data Lakehouse architectures. Its support for ACID transactions, schema evolution, time travel, and large-scale analytics has made it the go-to format for managing structured data at scale. As a result, Iceberg tables are heavily relied upon by data analysts, scientists, ML engineers, and reporting tools for everything from exploratory analysis to production-grade machine learning and BI dashboards. With so many downstream dependencies, maintaining the structural integrity of these tables is mission-critical.
However, even minor schema changes - like altering a column’s data type or dropping a field - can silently introduce breakages or skew downstream metrics.
Take, for example, Namrata, a data scientist who was working on a churn prediction model for a subscription platform. Midway through the quarter, an upstream table was modified- an is_active column was changed from a boolean to a string to accommodate new logic. The pipeline didn’t break, but downstream, the model began misclassifying users because it interpreted "false" as a truthy value. The issue went unnoticed for days until a business user questioned why churn predictions had spiked unexpectedly.
In another case, during the end-of-year holiday sales analysis for 2023, a revenue dashboard had relied on a field called discount_percent to calculate the impact of seasonal promotions. Sid, a junior engineer, deleted this column while cleaning up unused fields, assuming it was no longer referenced - after all, it wasn’t used in any of the team’s current pipelines. What he had missed was that a legacy reporting system downstream had used it to inform seasonal pricing strategy. The deletion caused the dashboard to display inflated revenue numbers for nearly a week before the anomaly was caught.
Most data platforms rely on internal change management practices, such as PR reviews and code validations. Yet, these are inherently reactive and often limited in catching issues that arise post-deployment. A single overlooked schema tweak can quietly propagate incorrect values through dozens of dependent pipelines, ultimately degrading data quality, analytics accuracy, or even ML model integrity.
These issues often surface only when business users flag inconsistencies in dashboards, or worse, when customers are impacted. By then, engineers are left scrambling—often during off-hours—to identify the root cause and deploy hotfixes.
Clearly, there’s a need for proactive, automated schema monitoring—something that acts as an early warning system before these issues snowball into production-level incidents.
The Drawing Board
We approached the problem with a sense of empathy, examining it from multiple angles to understand the inefficiencies in the resume evaluation process. It became clear that the system needed a comprehensive redesign to make it more effective and intuitive. Our envisioned solution focuses on building an efficient, user-friendly platform optimized for parsing, scoring, segmentation, and search, aimed at saving recruiters valuable time while enhancing decision-making.
The core of the system is designed with three key components:
Advanced Search Mechanism: This feature facilitates quick and precise filtering of resumes based on keywords, skills, and other critical attributes, enabling recruiters to find relevant profiles effortlessly.
Profile Scoring System: Profiles are evaluated independently for their overall quality and assessed against job-specific requirements using the Right Fit for Opportunity (RFFO) score, ensuring the best matches for open roles.
Segmentation and Filtering: By categorizing profiles into high, medium, and low suitability tiers, this functionality helps recruiters focus their attention on the most promising candidates.
This integrated approach ensures a scalable, efficient, and user-friendly system that empowers HR teams, hiring managers, and recruitment agencies to streamline their processes and make smarter hiring decisions.
The Blueprint and Workbench
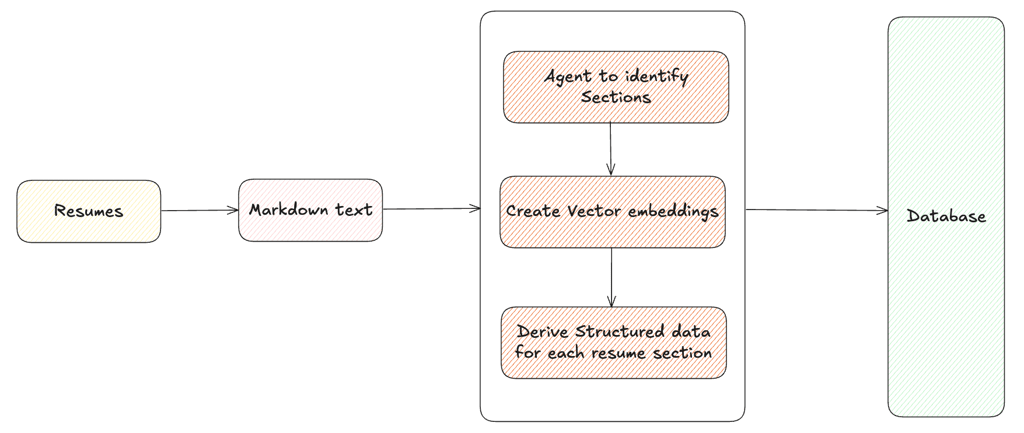
When a resume enters the system, the AI agent kicks off by autonomously processing the resume file, typically in PDF format, and converting it into a markdown format using tools like Docling. This converted content is then stored in a PostgreSQL database, ensuring it is structured and ready for further AI-driven actions and analysis. The system autonomously manages this workflow, enabling seamless and efficient resume processing.
Next comes Pre-Processing, where AI agents, driven by Large Language Model (LLM), autonomously interpret and organize the resume content.
1. Identify Sections of the Resume:
Using AI agent driven text analysis, the markdown version of the resume is systematically parsed to identify key sections such as Education, Skills, Experience, and Contact Details. This automated categorization ensures that the content is organized and ready for deeper insights.
2. Generate & Persist Vector Embeddings for Similarity Search:
After the sections are identified, an AI agent generates vector embeddings using the OpenAI embeddings model (text-embedding-ada-002). These embeddings, which are numerical representations of textual data, capture the semantic essence of each section and are stored in a dedicated table for resume sections.
The AI-powered vector embeddings add intelligence and efficiency to the system by:
i) Conducting similarity Searches: If a recruiter is searching for candidates with say “Frontend” experience, the system leverages embeddings to perform a semantic search. It identifies resumes with related skills like React, Angular, or JavaScript, even if the word "Frontend" doesn’t explicitly appear in the text.
ii) Adding Context for to LLM for Advanced Processing: The embeddings provide essential context for segmenting resumes based on specific criteria. This context is particularly valuable when resumes are processed further using large language models (LLMs), ensuring accurate and targeted results.
3. Derive Structured data for each segments:
In order to apply SQL filters to resume records, it is essential to have structured data for entities such as Education, Skills, Experience, and Contact Details. This structure enables answering queries like:
i) Find profiles with the current location as Bangalore.
ii) Find profiles with skills such as Python, AI, and Spark.
iii) Find profiles with more than four years of experience.
These LLM-driven steps transform resumes into structured, actionable data, optimizing the recruiter’s ability to identify the best candidates efficiently and effectively.