
Proactive Schema Change Alerts for Iceberg Tables: A Lightweight Monitoring Tool for Data Teams
The Challenge
Apache Iceberg has quickly become a cornerstone of modern Data Lakehouse architectures. Its support for ACID transactions, schema evolution, time travel, and large-scale analytics has made it the go-to format for managing structured data at scale. As a result, Iceberg tables are heavily relied upon by data analysts, scientists, ML engineers, and reporting tools for everything from exploratory analysis to production-grade machine learning and BI dashboards. With so many downstream dependencies, maintaining the structural integrity of these tables is mission-critical.
However, even minor schema changes - like altering a column’s data type or dropping a field - can silently introduce breakages or skew downstream metrics.
Take, for example, Namrata, a data scientist who was working on a churn prediction model for a subscription platform. Midway through the quarter, an upstream table was modified- an is_active column was changed from a boolean to a string to accommodate new logic. The pipeline didn’t break, but downstream, the model began misclassifying users because it interpreted "false" as a truthy value. The issue went unnoticed for days until a business user questioned why churn predictions had spiked unexpectedly.
In another case, during the end-of-year holiday sales analysis for 2023, a revenue dashboard had relied on a field called discount_percent to calculate the impact of seasonal promotions. Sid, a junior engineer, deleted this column while cleaning up unused fields, assuming it was no longer referenced - after all, it wasn’t used in any of the team’s current pipelines. What he had missed was that a legacy reporting system downstream had used it to inform seasonal pricing strategy. The deletion caused the dashboard to display inflated revenue numbers for nearly a week before the anomaly was caught.
Most data platforms rely on internal change management practices, such as PR reviews and code validations. Yet, these are inherently reactive and often limited in catching issues that arise post-deployment. A single overlooked schema tweak can quietly propagate incorrect values through dozens of dependent pipelines, ultimately degrading data quality, analytics accuracy, or even ML model integrity.
These issues often surface only when business users flag inconsistencies in dashboards, or worse, when customers are impacted. By then, engineers are left scrambling—often during off-hours—to identify the root cause and deploy hotfixes.
Clearly, there’s a need for proactive, automated schema monitoring—something that acts as an early warning system before these issues snowball into production-level incidents.
The Approach
To address this gap, we developed a lightweight tool designed to automatically detect and notify teams of schema drifts in Iceberg tables - before they cause downstream disruptions.
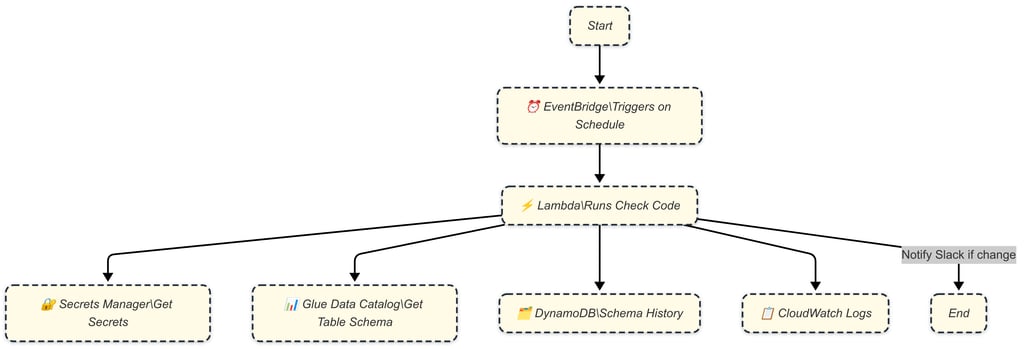
This tool, built around AWS-native services, runs as a scheduled Lambda function. It tracks schema evolution across pre-configured Glue databases and tables, comparing current schemas to historical snapshots. On detecting changes, it sends real-time alerts to communication channels like Slack or Microsoft Teams.
The core focus: proactive visibility and reduced firefighting.
Not a Replacement - A Complement to Code Reviews
While code reviews remain an essential step in any data engineering workflow, they’re not always foolproof in detecting non-breaking schema changes. For example, a change in a numeric column’s precision may not throw an error but can still distort aggregates and insights.
This tool acts as a safety net. By continuously monitoring production tables and independently verifying schema changes, it ensures that even subtle shifts don’t go unnoticed. It’s not meant to replace existing review processes, but to augment them with real-time monitoring and early alerts.
This becomes particularly important in complex pipelines where a single SQL transformation might touch multiple source tables, making manual tracking infeasible and error-prone.
Under the Hood: Technical Stack & Architecture
AWS Lambda: Executes schema monitoring logic on a schedule.
Glue Catalog: Serves as the source of truth for schema metadata.
DynamoDB: Maintains historical schema versions for comparison.
EventBridge: Triggers the Lambda function at configured intervals.
Slack/Teams API: Sends real-time alerts on schema changes.
How It Works
Fetch Table Schema
Uses the get_table API from AWS Glue to retrieve the latest schema of each configured Iceberg table.Persist Schema History
The current schema is versioned and stored in DynamoDB using a unique key comprising the database and table name.Detect Changes
Compares the current schema to its previous version. If a difference is detected—like column addition, removal, or data type modification—it flags it as a drift.
Send Notifications
A concise, human-readable summary of the schema change is pushed to your team via Slack or Microsoft Teams, enabling immediate awareness and response.
Deployment
The project code is available in this github repo - https://github.com/datafarer/iceberg-tables-schema-drift-alerts
This monitoring tool is designed to be lightweight, scalable, and non-intrusive. You can deploy it in under 15 minutes using CloudFormation. Once active, it silently guards your Iceberg tables, detecting anomalies and alerting teams in real time.
Conclusion
In the world of data engineering, the best firefighting is the kind you never have to do. This tool brings calm to the chaos by acting as a sentinel - always watching, always ready to notify - so that schema changes don’t derail your workflows.
Whether you're building data platforms for Fortune 500s or startups, proactive schema change detection is a simple yet powerful way to protect data integrity and give your team peace of mind.