
Building Highly Scalable RAG Data Pipelines: Distributed Processing of Embeddings and Text Transformations
Problem Statement
As we push the boundaries of Agentic AI - intelligent, autonomous applications mostly built in Python - one persistent limitation keeps surfacing now and then: single-threaded execution.
Many AI workflows, including Retrieval-Augmented Generation (RAG) systems, still run sequentially. This design prevents them from utilizing the full power of modern multi-core CPUs or distributed clusters.
For example, RAG (Retrieval-Augmented Generation) applications require extensive data pre-processing: chunking, generating embeddings, and ingesting into vector databases. When this is done sequentially, pipelines become slow, resource-inefficient, and difficult to scale.
By adopting distributed processing frameworks like Apache Spark, these same workflows can be parallelized - leveraging all available cores, GPUs, and cluster nodes for:
Massively distributed processing
Better fault tolerance and debugging
Seamless and Native integration with cloud storage: S3, GCS, ADLS, HDFS
Data versioning and governance via Open Table formats: Delta Lake, Iceberg
The Challenge
Processing large volumes of documents for AI applications like Retrieval-Augmented Generation (RAG) or semantic search is no longer straightforward. While AI models often get the spotlight, the real bottleneck frequently lies in preparing the data efficiently.
Consider a team working on a large-scale RAG pipeline. Sequentially embedding 1 million documents on a single GPU could take nearly 3 days. Chunking large documents, embedding them individually, and sequentially storing them in a vector database created long processing times, limited scalability, and operational challenges.
Manual scripts or ad hoc solutions are insufficient as they lack automation, observability, and recovery. The result: under utilized infrastructure and delayed AI delivery.
In short:
Sequential embedding of 1M documents on a single GPU takes ~3 days
Chunking, embedding, and sequential storage create long processing times
Manual methods break under scale
The Approach
To tackle this challenge, we implemented a distributed compute pipeline using Apache Spark, a Python-native framework that allows parallelization of tasks across multiple CPUs and GPUs.
Why Spark?
Distributed task scheduling for low-latency workflows
Efficient GPU/CPU utilization for embeddings
Python integration with Hugging Face, PyTorch, TensorFlow, OpenAI
Resilient distributed datasets, automatic retries, cluster-level task management
How It Works
Chunking Documents
Documents are split into smaller chunks (e.g., 500–1000 tokens), allowing distributed processing across nodes.Embedding Chunks
Each chunk is processed in parallel on GPUs or CPUs, generating embeddings efficiently.
Example: OpenAI Ada embeddings with batch size 32.Storing & Indexing
Embeddings are stored in a vector database (e.g., Qdrant, FAISS, Milvus, Pinecone) for fast retrieval in RAG pipelines.
By parallelizing these steps, the pipeline reduces compute time dramatically while supporting millions of documents.
Step 2: Chunking the documents
Step 3: Generating the Embeddings
Step 4: Storing the Embeddings
Step 1: Creating Spark Dataframe from HotpotQA dataset
Benefits:
Scalability: Millions of documents without memory bottlenecks
Reliability: Automatic retries, task tracking
Flexibility: Supports different chunking strategies and embedding models
Under the Hood: Technical Stack
Orchestration: Apache Spark
Embedding & ML: Hugging Face, PyTorch, TensorFlow, OpenAI
Vector Database: Qdrant
Data System: Delta Lake, Iceberg, S3, GCS, ADLS
Conclusion
Distributed chunking and embedding form the backbone of scalable RAG systems.
By leveraging Spark’s distributed architecture, AI teams can move beyond sequential Python workflows - achieving high throughput, reproducibility, and resilience.
As organizations move toward agentic and real-time AI, scalable data pipelines will matter as much as the models themselves. The future of RAG lies not just in smarter LLMs, but in smarter data foundations.
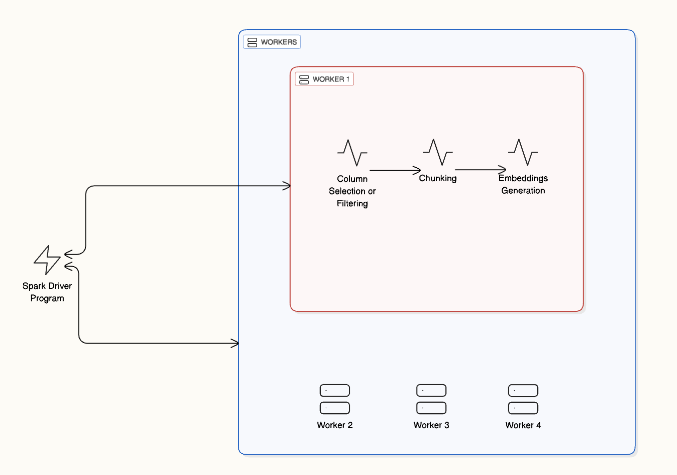
Spark Distributed Processing in Action: Not Just Faster - Smarter